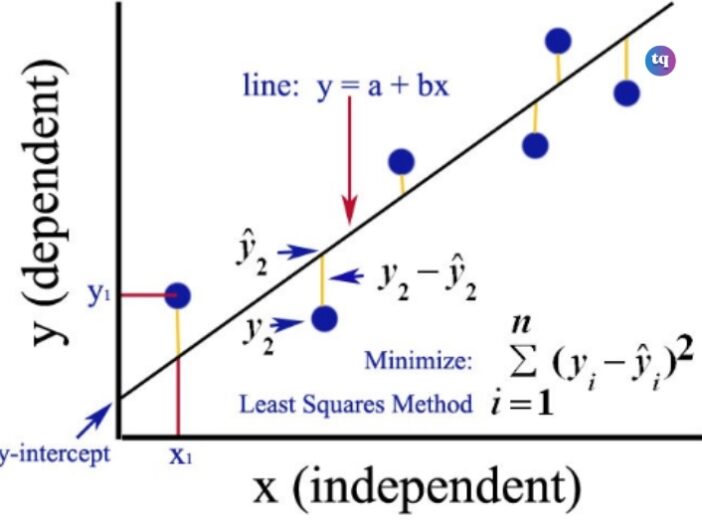
Have you ever wondered how to find the best line that fits a set of data points? Or how to measure the relationship between two variables, such as height and weight or income and education? If yes, you might want to learn about Ordinary Least Squares (OLS) regression.
It is a powerful and widely used statistical technique that can help you answer these questions and more. However, in this blog article, you will understand what OLS regression is, how it works, and what its advantages and limitations are.
So, by the end of this post, you will have a solid understanding of OLS regression and how to apply it to your data problems.
Table of Contents
Definition of Ordinary Least Squares OLS Regression
OLS, or Ordinary Least Squares, is a method of estimating the unknown parameters in a linear regression model by minimizing the sum of the squared errors between the observed and predicted values of the dependent variable.
Ordinary Least Squares (OLS) regression is also the optimization technique that enables you to locate a straight line as near to your data points as feasible in a linear regression model.
How Does OLS Apply To Linear Regression?
Linear regression is a set of algorithms used in supervised machine-learning projects. Further, classification and regression are the two main categories into which supervised machine learning tasks fall, and linear regression algorithms fall into the latter.
It is different from classification because of the nature of the target variable. A categorical value, such as “yes/no,” “red/blue/green,” “spam/not spam,” etc., is the aim of classification. However, the goal of regression is to find numerical, continuous values.
Consequently, instead of being asked to predict a class or category, the algorithm will be asked to predict a continuous number. If, for example, you wish to predict the cost of a house based on a few relative features, the price—a continuous number—will be the model’s output.
In addition, you can categorize regression tasks into two basic groups: those that utilize a single feature to predict the target and those that use many features. Let’s look at the aforementioned house task as an example.
You will fall into the first category if your goal is to estimate a house’s price solely on its square meters. However, if your goal is to estimate a house’s price based on its square meters, location, and how livable the neighborhood is, you will fall into the second category for multiple features.
So, you’ll probably use a simple linear regression approach in the first case, which we’ll talk about in more detail later in this post. On the flip side, you will probably use a multiple linear regression if you have more than one feature to explain the target variable.
One statistical model that is frequently employed in machine learning regression problems is simple linear regression. Its foundation is the notion that the following formula can be used to explain the relationship between two variables:
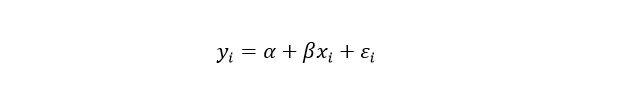
Where:
- α, and β are the actual (but unseen) parameters of the regression.
- εi is the error term.
- When there is a unitary variation in the independent variable, the parameter β represents the dependent variable’s variation.
- Conversely, when the independent variable equals zero, the parameter α represents the value of the dependent variable.
How To Find OLS in a Linear Regression Model
Finding the parameters α and β for which the error term is minimized is the aim of simple linear regression. So, the model will minimize the squared errors, to be more exact. Since the negative mistakes are penalizing our model equally, we don’t want them to make up for the positive ones.
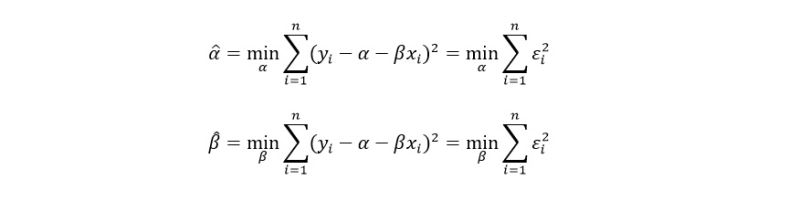
This process is termed the ordinary least squares (OLS) error.
Let’s walk you through those optimization issues one by one. Reframing our squared error sum below, we have:
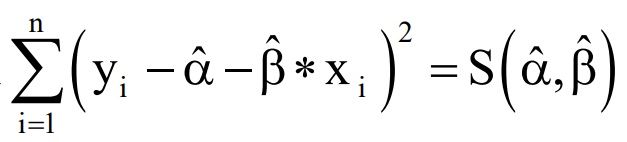
We can set our optimization problem this way:
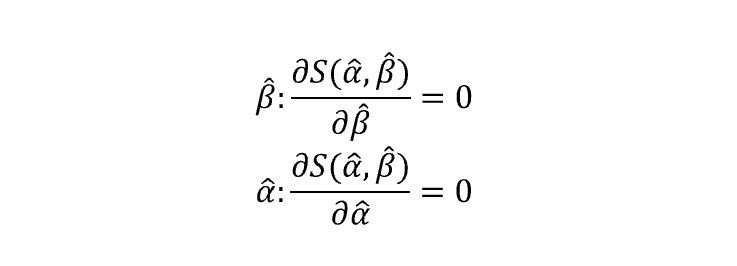
So, let’s begin with β:
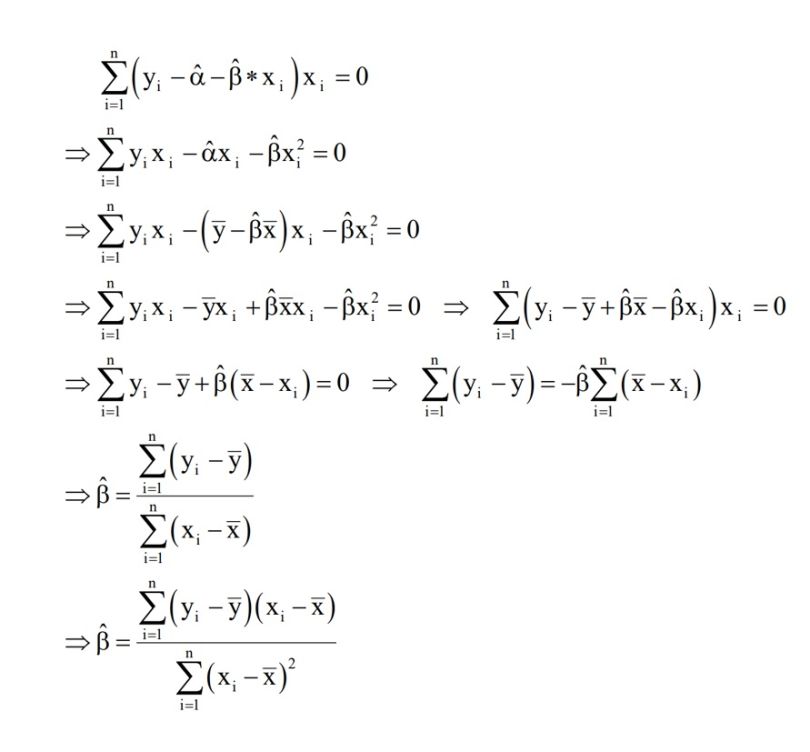
Understanding that the sample covariance between two variables is given by:
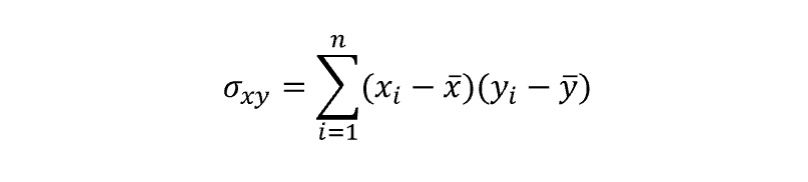
And that the sample correlation coefficient between two variables is equivalent to:
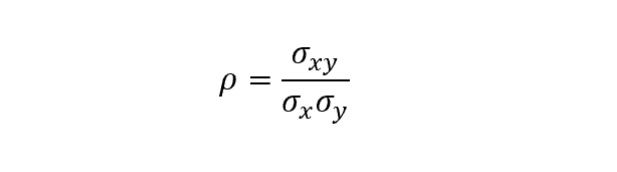
We can reframe the expression above as follows:
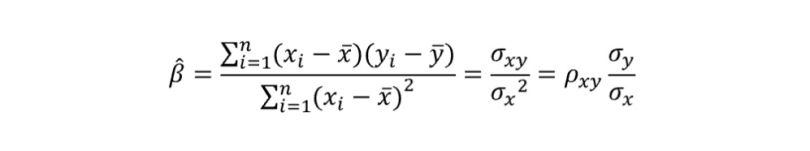
The same reasoning stands for our α:
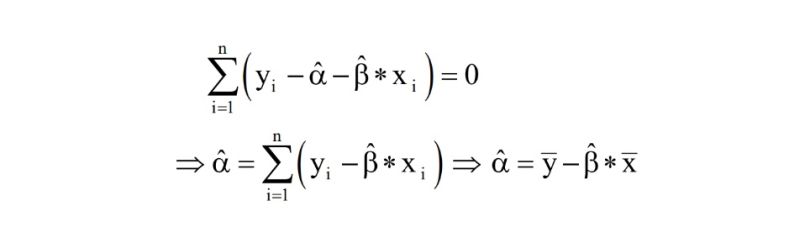
Immediately you obtain, those values of α and β, which minimize the squared errors, our model’s equation will look as follows:
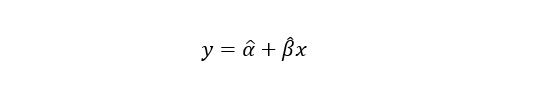
What Are The Advantages of OLS Regression?
In summary, consider OLS as an optimization technique to derive a straight line from your model that is as close to your data points as possible. Although there are other optimization strategies as well, OLS is the most often used for tasks of this nature.
This is because the coefficients produced by the regression are unbiased estimators of the true values of alpha and beta.
The OLS estimators α and β are the best linear unbiased estimators (BLUE) of the real values of α and β under certain assumptions of the linear regression model (random sampling of observations, linearity in parameters, conditional mean equal to zero, absence of multicollinearity, and homoscedasticity of errors), according to the Gauss-Markov Theorem.
Limitations of Ordinary Least Squares Regression
OLS is a widely used technique in statistics and data analysis, but it also has some limitations that you must consider. Some of the limitations of OLS are:
Linearity assumption: OLS assumes that the relationship between the independent and dependent variables is linear, or can be approximated by a linear function. This means that OLS may be unsuitable for modeling nonlinear or complex relationships, such as exponential, logarithmic, or polynomial functions. If the linearity assumption is violated, the OLS estimates may be biased.
Normality assumption: Ordinary Least Squares assume that the errors (or residuals) of the regression model are normally distributed with zero mean and constant variance. Therefore, OLS may not be appropriate for modeling data that have skewed, heavy-tailed, or heteroscedastic errors.
Independence assumption: It assumes that the errors of the regression model are independent of each other and the independent variables. Thus, OLS may not be applicable for modeling data that have autocorrelated, spatially correlated, or multicollinear errors.
Outliers and influential points: OLS is sensitive to outliers and influential points. And these are observations that have a large impact on the regression results. Outliers and influential points may arise from measurement errors, data entry errors, or extreme values in the data.
Bottom Line
OLS regression is a useful and versatile tool that can help you understand and explain various phenomena in data. However, it is not a perfect method. Meanwhile, it has some assumptions and conditions that you must meet for valid results.
Therefore, you should always check the quality and suitability of your regression model before drawing any conclusions or making any decisions based on it.