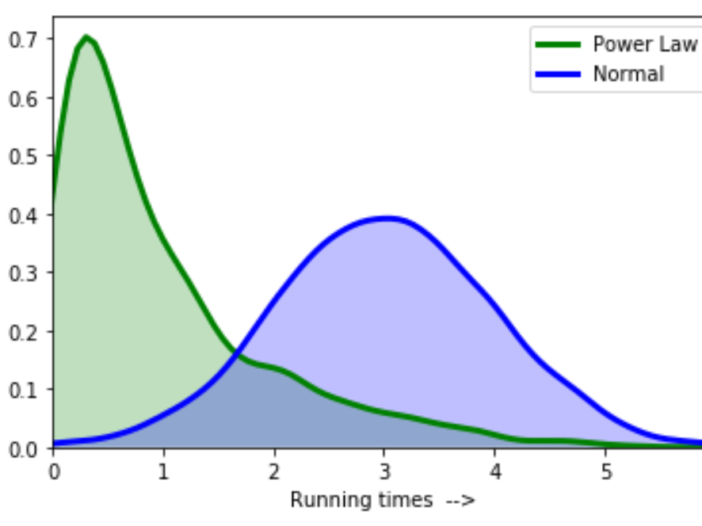
Using the Box-Cox transformation, you can statistically alter your target variable to make your data more akin to a normal distribution.
Many statistical methods operate under the assumption that errors are distributed regularly. This assumption enables you to create confidence intervals and do hypothesis tests.
If your errors aren’t already normal, you should be able to normalize them by changing your target variable. Furthermore, because transformations can eliminate white noise, they can increase the predictive strength of your models.
In this guide, we’ll take you through the box-cox transformation and target variable. So, read on.
Table of Contents
What is Box-Cox Transformation?
A Box-Cox transformation is a statistical technique for transforming non-normal dependent variables into a normal shape. It is a useful technique to meet the assumptions of equal variance and normality needed by many statistical tests.
In essence, the Box-Cox transformation calculates an optimal power transformation that makes the distribution of the variable more normal. It does this by raising the variable to a power λ via:
(y^λ – 1) / λ, if λ ≠ 0
log(y), if λ = 0
Where:
y is the dependent variable and
λ is the transformation parameter.
Different values of λ result in different transformed variables. So, common λ values are:
λ = 1: No transformation
λ = 0: Log transformation
λ = 0.5: Square root transformation
Further, the optimal λ value that maximizes normality is estimated via maximum likelihood. Once λ is estimated, you transform ‘y’ using that parameter. This optimally transformed variable can now be used in statistical tests like ANOVA, regression, etc.
Overall, the Box-Cox transformation is a handy way to normalize non-normal variables by raising them to an estimated optimal power that maximizes normality. It expands the capabilities of common statistical tests.
Why Use The Box-Cox Transformation?
The Box-Cox transformation is employed for the following primary reasons:
- To Meet the Assumptions of Statistical Tests. The dependent variable in many parametric statistical techniques, such as ANOVA, linear regression, and t-tests, is assumed to have equal variance and to be normally distributed. But when a variable is significantly non-normal, the Box-Cox transformation aids in meeting these important requirements.
- Transform Skewed Data. Positive or negative skew in the data can produce biased inferences and outcomes. However, with the aid of the improved Box-Cox power transformation, a more symmetrical, normal shape is achieved for both positively and negatively skewed data.
- Stabilize Variance. By decreasing heterogeneous variances across values, Box-Cox transformations can equalize highly variable data like minimizing skew. Again, this stabilization meets the requirements of parametric models.
- Enhance Diagnostics. Model diagnostics are hampered by a large degree of skew, non-constant variance, and non-normality, which are evident on residual plots, Q-Q plots, etc. However, the change enhances plots and distributions.
- Robust Parameter Estimates. Data that has been normalized for homogeneous variance and decreased bias can be used to estimate model coefficients, effects, and outcomes in a way that is more effective, objective, and reliable.
Essentially, meeting normality and variance assumptions through Box-Cox expands the acceptable and moral use of standard statistical techniques to more imperfect, real-world datasets, hence enhancing conclusions.
What is a Target Variable?
A target variable is the variable you are attempting to estimate. The benefit of the linear regression model is that it allows you to use almost any type of target variable, including continuous, ordinal, binary, and more.
That being said, your slope parameters will be interpreted differently depending on the target variables you use. For instance, if your target variable is binary (meaning it can only take on a value of one or zero), the slope parameters of your regression model show how a one-unit increase in your independent variables affects the likelihood that your target variable will equal one.
What is The Box-Cox Transformation Equation?
Let’s say w is a transformed variable and “y” is a target variable, then the Box-Cox transformation equation will be like this:
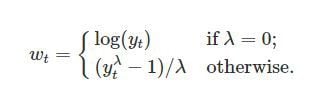
In this equation, “t” represents the time while lambda represents the parameter that we picked. Additionally, you can carry out the Box-Cox transformation on non-time series data.
See what happens when lambda equals one. In such a scenario, your data shifts down, however, the shape of the data does not change.
So, if one is the optimal value for lambda, it means the data is already distributed normally, and the Box-Cox transformation is not necessary.
How To Choose Lambda
The most common method for choosing lambda is to use the maximum likelihood estimate of lambda provided in the boxcox() function. This finds the parameter that maximizes the normality of the transformed variable. Thus, using the data-driven MLE lambda is the standard approach.
Sometimes pre-chosen values like 0 (log), 0.5 (square root), 1 (no transformation), etc. provide interpretable transformations. While less optimized for normality, the simplicity can aid analysis.
Further, in the graphical selection, the boxcox() plot showing the normality likelihood across lambda values can guide the selection of an appropriate visible elbow/peak value if the MLE seems an outlier or overfit level.
In addition, you can transform with 2-3 candidate lambda values, fit models, and compare performance metrics like AIC, and BIC using anova() to select the final superior lambda.
In practice, the data-driven MLE lambda is preferred for automation and optimization. However, the flexibility to override with theoretical or graphical selection permits catering transformations to the analysis context.
Read this article: High-Level vs. Low-Level Programming Languages, Explained
Box-Cox Transformation Limits
The Box-Cox transformation might not be the best option if interpretation is your main concern. The changed target variable might be more challenging to understand than if we had just done a log transform if lambda is non-zero.
Another problem is that, when we return the modified data to its original scale, the Box-Cox transformation typically yields the median of the predicted distribution. But more often, there are several methods for obtaining the mean when we desire it rather than the median.
You now understand the constraints of the Box-Cox transformation and how it is implemented in Python.
Conclusion
The Box-Cox transformation is a crucial statistical tool for adjusting non-normal model variables into an optimal normal shape.
By estimating the power parameter λ that maximizes normality likelihood and transforming variables via y^λ, the technique uniquely conditions each target variable based on its distribution.
This satisfies the critical assumptions of equal variance and normality required by popular inferential tests like ANOVA, regression, etc.